为什么苹果M1芯片这么快?一份最易懂的技术指南解析计算机系统集成
苹果M1芯片自发布以来,以其惊人的性能与能效震撼了整个科技界。许多人都在问:它为什么能这么快?答案的核心,其实在于苹果通过软硬件深度整合,实现了一种前所未有的计算机系统集成。下面,我们将通过一份详细易懂的技术指南,为你揭示M1芯片速度背后的秘密。
一、统一的架构:从“各自为政”到“融为一体”
传统PC通常采用分离式设计:中央处理器(CPU)、图形处理器(GPU)、内存等由不同厂商提供,通过主板上的总线连接。这种设计虽然灵活,但组件间的通信存在延迟和功耗损失。
M1芯片则采用了片上系统(SoC)设计,将CPU、GPU、神经网络引擎(NPU)、内存、安全芯片等所有核心组件,全部集成到一块小小的芯片上。这带来了两大革命性优势:
- 极低的通信延迟:组件之间的数据交换直接在芯片内部进行,速度远超传统需要通过主板线路传输的方式。
- 极高的能效比:数据无需长距离“奔波”,大大降低了功耗,这也是M1设备续航惊人的关键。
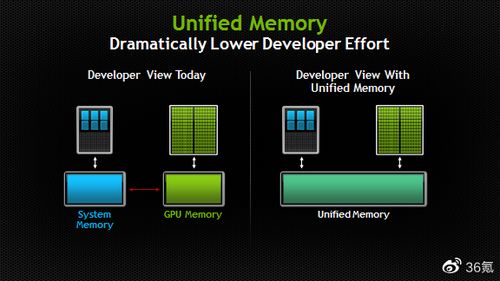
二、内存统一:告别“数据搬运”的瓶颈
在传统架构中,CPU和GPU通常拥有各自独立的内存。当GPU需要处理CPU的数据时,必须先将数据从系统内存复制到自己的显存中,这个过程耗时耗能。
M1芯片采用了统一内存架构(UMA)。CPU、GPU和其他核心共享同一块高带宽、低延迟的内存池。这意味着:
- 数据无需复制:GPU可以直接访问CPU处理过的数据,反之亦然,极大地加速了图形、视频处理等需要两者协作的任务。
- 内存利用率最大化:避免了因数据副本而浪费内存空间。
三、强大的自研核心:ARM架构与苹果的深度优化
M1芯片放弃了传统的x86架构,转向了更现代、更高效的ARM架构。苹果基于ARM指令集,自主研发了Firestorm(高性能)和Icestorm(高能效)CPU核心。
- 大小核设计:M1将4个高性能核心与4个高能效核心集成在一起。系统智能分配任务:重负载交给大核全力冲刺,后台轻任务则由能效小核默默处理,从而实现性能与续航的完美平衡。
- 惊人的单核性能:得益于先进的5纳米制程工艺和苹果深厚的微架构设计,M1的单核性能超越了同期许多桌面级CPU,这直接决定了日常使用的流畅度。
四、软硬件终极协同:生态系统是“加速器”
苹果掌控着从芯片(硬件)到macOS(软件)的整个生态链,这使其能进行深度的垂直优化。
- macOS Big Sur及后续系统是专为M1芯片设计的。系统能精准调度芯片的每一个核心,充分发挥其潜力。
- Rosetta 2转译技术:为了让原有的x86应用能在M1上运行,苹果开发了高效的转译层。它并非简单模拟,而是在安装时就将大部分指令“翻译”成M1原生指令,因此运行转译应用的效率也远超预期。
- 原生应用爆发:越来越多的开发者推出了针对M1优化的原生应用(Universal 2),这些应用能够同时调用CPU、GPU和NPU,速度得到数量级的提升。
五、专用处理单元:让专业任务“飞”起来
M1芯片集成了多个专用处理单元,用于处理特定任务:
- 16核神经网络引擎(NPU):专门用于机器学习任务,如人脸识别、语音处理等,速度提升最高达15倍。
- 强大的媒体处理引擎:专门用于H.264/HEVC视频的编解码,让Final Cut Pro等软件处理4K、8K视频如行云流水,且功耗极低。
- 安全隔区:集成独立的安全芯片,处理加密、身份认证等任务,既安全又不占用主系统资源。
集成是王道
苹果M1芯片的“快”,并非单一技术的突破,而是通过系统级集成带来的全方位革命。它将先进的制程工艺、创新的统一内存架构、自研的高效CPU/GPU核心、专用的处理单元,以及深度协同的软件操作系统,全部无缝融合在一起。这打破了传统计算机各组件间的隔阂,让数据以最短路径、最高效率被处理,从而实现了性能与能效的飞跃。M1的成功,也为未来个人计算的发展指明了一个清晰的方向:更深度的软硬件整合与系统级优化。
如若转载,请注明出处:http://www.qingdong999.com/product/85.html
更新时间:2026-04-06 16:44:24